The only way to achieve reasonable user privacy is to avoid collecting this information in the first place. This is harder to do from an engineering perspective, but we believe it is the correct approach.The Venice API replicates the same backend privacy architecture as the Venice platform: requests pass through the Venice proxy over encrypted connections, Venice does not store or log prompt and response content for normal inference, and each selected model adds one of four privacy modes at the runtime layer: Anonymous, Private, TEE, or E2EE.
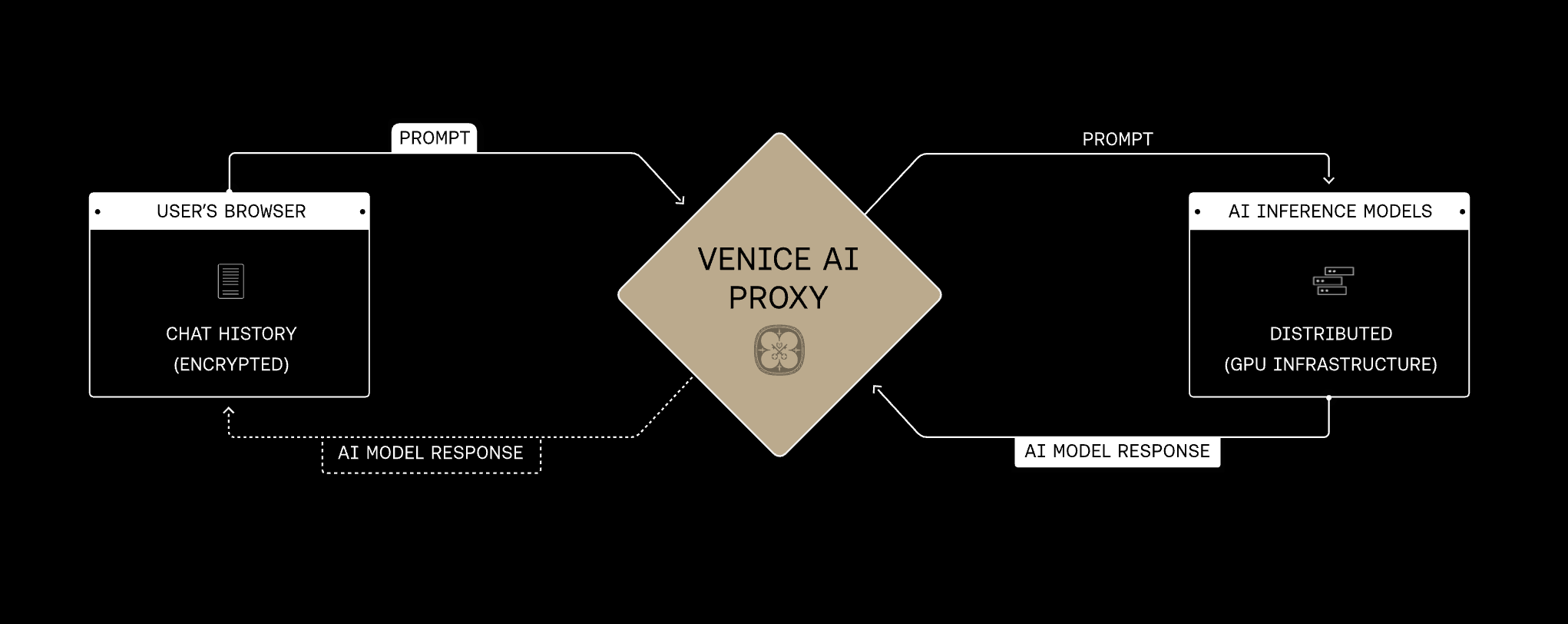
Privacy architecture
The Venice proxy is the shared foundation for every privacy mode. Requests pass through Venice over HTTPS/TLS and are relayed without Venice storing prompt or response content. The privacy mode on the selected model determines what happens next at the provider or model runtime layer. Venice presents model privacy in four modes. They build on the same proxy foundation and add progressively stronger protections, from obscuring identity from the provider to encrypting prompts end-to-end into a verified enclave.Increasing privacy protection
Anonymous
Identity obscured from provider
Venice proxies the request without sending your Venice identity to the model provider. Prompt content is still visible to that provider.
Private
Zero data retention, contract-enforced
Prompt and response content is processed for inference only and is not retained after the request completes.
TEE
Hardware-isolated inference
Supported models run inside a Trusted Execution Environment with remote attestation support.
E2EE
End-to-end encrypted to a verified TEE
Your client encrypts the prompt before sending it. Venice relays ciphertext, and only the verified TEE decrypts it.
/models endpoint tells you each model’s privacy level. Models marked as anonymized are Anonymous models, and models marked as private are Private models. TEE and E2EE are shown separately in the model’s capabilities, such as supportsTeeAttestation and supportsE2EE.
For implementation details, see the TEE & E2EE models guide.
TEE and E2EE
TEE and E2EE models add cryptographic and hardware-backed controls on top of Venice’s default no-content-retention approach.Use TEE when
You want the model to run inside an attested hardware enclave, but your client can send plaintext prompts over the normal API request.
Use E2EE when
You want prompts encrypted before they leave your client and decrypted only inside a verified TEE.
/chat/completions with E2EE-capable models. Your client must fetch attestation, verify the nonce and enclave evidence, encrypt user and system messages, send the X-Venice-TEE-* headers, stream the response, and verify/decrypt response content.
E2EE also disables features that need plaintext outside the enclave, such as web search, memory, summaries, some tool flows, and other server-side processing.
Choosing a model
Use/models to see what privacy protections each model supports before you send a request.
Each model has two relevant fields:
model_spec.privacytells you the model’s baseline privacy mode:anonymized: Venice hides your identity from the provider, but the provider may still see the prompt.private: Venice routes the request through zero-data-retention infrastructure.
model_spec.capabilitiestells you whether the model supports stronger protections:supportsTeeAttestation: the model can run inside a verifiable Trusted Execution Environment.supportsE2EE: the model can accept client-encrypted prompts that are decrypted only inside the TEE.
private for zero data retention, choose tee: true for hardware-backed isolation, and choose e2ee: true when you need prompts encrypted before they leave your client.